



In today’s digital age, data is king. Companies of all sizes are collecting and analyzing data to make informed business decisions and gain a competitive edge. However, with the vast amount of data being collected, it can be challenging to manage and organize it effectively. This is where databases come in. Databases are essential tools for storing, organizing, and retrieving data efficiently. In this article, we will explore how to optimize your database by converting flat files to a database using the popular Python library, pandas.
Why Optimize Your Database?
Before we dive into the process of converting flat files to a database, let’s first understand why it is essential to optimize your database.
Improved Performance and Efficiency

by Resource Database (https://unsplash.com/@resourcedatabase)
One of the main reasons to optimize your database is to improve its performance and efficiency. As your database grows, it can become slower and less efficient, making it challenging to retrieve data quickly. By optimizing your database, you can improve its speed and efficiency, making it easier to access and analyze data.
Better Data Organization
Flat files, such as CSV or Excel files, are great for storing data in a simple and easy-to-read format. However, as your data grows, it can become challenging to organize and manage it effectively. Databases offer a more structured and organized way of storing data, making it easier to query and analyze.
Enhanced Data Security
Databases offer better data security compared to flat files. With databases, you can set up user permissions and access controls to ensure that only authorized users can access sensitive data. This is especially crucial for companies that handle sensitive customer information.
Converting Flat Files to a Database with Pandas
Now that we understand the importance of optimizing your database let’s explore how to convert flat files to a database using pandas.
What is Pandas?
Pandas is a popular Python library used for data manipulation and analysis. It offers powerful tools for reading, writing, and manipulating data in various formats, including CSV, Excel, and databases. In this article, we will focus on using pandas to convert flat files to a database.

Installing Pandas
Before we can start using pandas, we need to install it. If you already have Python installed on your system, you can install pandas using the pip package manager. Open your terminal or command prompt and enter the following command:
pip install pandas
Importing Pandas
Once pandas is installed, we can import it into our Python script or Jupyter Notebook. To do this, we use the import statement:
import pandas as pd
The as pd part of the statement allows us to refer to pandas as pd in our code, making it easier to use.
Reading Flat Files with Pandas
Pandas offers a variety of functions for reading data from different file formats. For flat files, we can use the read_csv() function. Let’s say we have a CSV file called sales_data.csv that contains sales data for our company. We can read this file into a pandas DataFrame using the following code:
df = pd.read_csv(‘sales_data.csv’)
The read_csv() function takes in the path to the CSV file as its argument and returns a DataFrame object. A DataFrame is a two-dimensional data structure that resembles a table, with rows and columns.
Exploring the DataFrame
Before we can convert our flat file to a database, let’s first explore the DataFrame to get a better understanding of our data. We can use the head() function to view the first five rows of our DataFrame:
df.head()
This will display the first five rows of our DataFrame, giving us a glimpse of our data. We can also use the info() function to get more information about our DataFrame, such as the number of rows and columns, data types, and memory usage:
df.info()
Converting Flat Files to a Database
Now that we have our data in a DataFrame, we can convert it to a database using pandas. To do this, we will use the to_sql() function. This function takes in the name of the database table we want to create and the database connection object. Let’s break down the process into steps.
 CSV files can be used to share additional columns beyond a single metric
CSV files can be used to share additional columns beyond a single metricStep 1: Create a Database Connection
Before we can convert our DataFrame to a database, we need to establish a connection to the database. We can use the create_engine() function from the sqlalchemy library to create a database connection. This function takes in the database type, username, password, host, and database name as arguments. For example, if we are using MySQL, our connection string would look like this:
engine = create_engine(‘mysql://username:password@host/database_name’)
Step 2: Convert DataFrame to a Database Table
Next, we can use the to_sql() function to convert our DataFrame to a database table. Let’s say we want to create a table called sales in our database. We can use the following code:
df.to_sql(‘sales’, con=engine)
This will create a new table called sales in our database and insert all the data from our DataFrame into it.
Step 3: Specify Data Types
By default, pandas will try to infer the data types of our columns and create the corresponding data types in the database table. However, we can also specify the data types for each column using the dtype argument. For example, if we want the price column to be of type DECIMAL(10,2), we can use the following code:
df.to_sql(‘sales’, con=engine, dtype={‘price’: DECIMAL(10,2)})
This will ensure that the price column in our database table is of type DECIMAL with a precision of 10 and a scale of 2.
Step 4: Append Data to an Existing Table
If we want to add new data to an existing table in our database, we can use the if_exists argument. By default, this argument is set to fail, which means that if the table already exists, an error will be thrown. However, we can change this to append to add the new data to the existing table. For example:
df.to_sql(‘sales’, con=engine, if_exists=’append’)
This will add the new data to the existing sales table in our database.
AmetricX to Database with Pandas
For more information read the Generate API Key documentation
Navigate to settings from the top bar

Under API KEYS click on Add Api Key
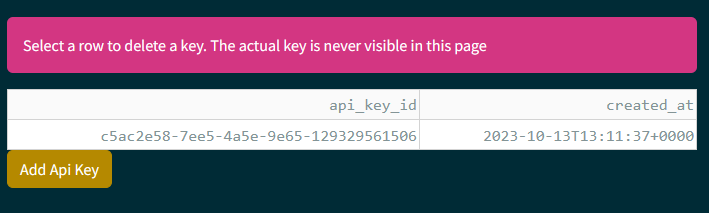
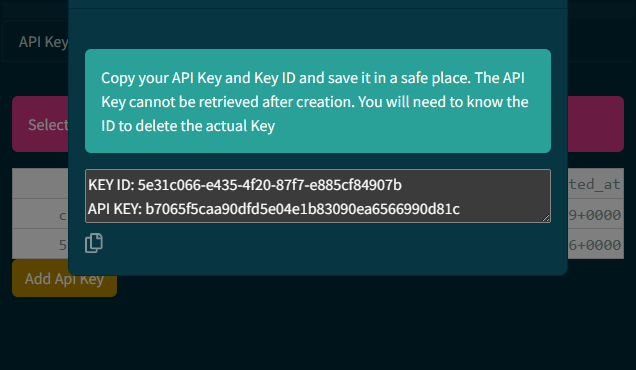
Click on Add Api Key to create a new key).The actual key will display only once and cannot be retrieved afterward.
 Start Sharing CSV files FREE today
Start Sharing CSV files FREE todayFor additional details, read the CSV File Exchange API documentation
import pandas as pd
file_id = <FILE ID> # See examples to get the FILE ID https://docs.ametricx.com/file_api/reference/#curl-example_1
df = pd.read_csv(
'https://trial.ametricx.com/api/v1/file/download/{file_id}'.format(file_id=file_id),
storage_options={'Authorization': 'Bearer <YOUR API KEY>)
We use sqlalchemy to create and “engine” to pass to pandas
import sqlalchemy as sa
engine = sa.create_engine('postgresql://ametricx:ametricx@localhost:5432/ametricx')For this example, we append the data to an existing table. Please read the pandas.Dataframe.to_sql documentation for additional details
df.to_sql('metrics_store', engine, if_exists='append', index=False)import pandas as pd
import sqlalchemy as sa
file_id = FILE_ID # See examples to get the FILE ID https://docs.ametricx.com/file_api/reference/#curl-example_1
df = pd.read_csv(
"https://trial.ametricx.com/api/v1/file/download/{FILE_ID}".format(FILE_ID=FILE_ID),
storage_options={'Authorization': 'Bearer {API_KEY}'.format(API_KEY=API_KEY)})
engine = sa.create_engine('postgresql://ametricx:ametricx@localhost:5432/ametricx')
df.to_sql('metrics_store', engine, if_exists='append', index=False)Conclusion
In this article, we explored the importance of optimizing your database and how to convert flat files to a database using pandas. By using pandas, we can easily read and manipulate data from flat files and convert it to a database, making it easier to manage and analyze. With the right tools and techniques, you can optimize your database and make the most out of your data.


